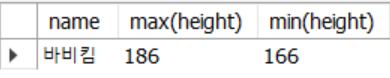[DB_MySQL] 이것이 MySQL이다 ch06 SQL 기본 문법 2 (WHERE, BETWEEN, IN, LIKE, 서브쿼리)
bobo122023. 2. 6. 18:52
728x90
반응형
1. 특정 조건의 데이터만 조회 <SELECT ... FROM ... WHERE>
◎ 기본적인 WHERE절
▷ 조회하는 결과에 특정한 조건을 줘서 원하는 데이터만 보고 싶을 때 사용
▷ SELECT 필드이름 FROM 테이블이름 WHERE 조건식;
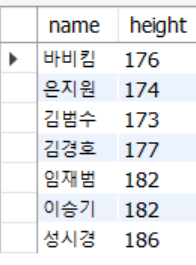
SELECT B* FROM usertbl WHERE name = '김경호';
◎ 관계 연산자의 사용
▷ OR 연산자 : '...했거나', '...또는'
▷ AND 연산자 ; '...하고', '...면서', '...그리고'
▷조건 연산자(=, <, >, <=, >=, < >, != 등)와 관계 연산자(NOT, AND, OR 등)를 조합하여 데이터를 효율적으로 추출 가능
SELECT userID, Name FROM usertbl WHERE birthYear >= 1970 AND height >= 182;
◎ BETWEEN... AND와 IN() 그리고 LIKE
▷ 데이터가 숫자로 구성되어 있으며 연속적인 값 : BETWEEN ...AND 사용
SELECT name, height FROM usertbl WHERE height BETWEEN 180 AND 183;
▷ 이산적인(Discrete) 값의 조건 : IN() 사용
▶ 여러개의 OR 사용 대신 IN 사용
select name, addr from usertbl where addr in('경남', '전남', '경북');
select name, mobile1 from usertbl where mobile1 in('011', '016', '018', '019');
▷ 문자열의 내용 검색 : LIKE 사용(문자뒤에 % - 무엇이든 허용, 한 글자와 매치 '_' 사용)
1. 김씨 찾기
-- 문자열 검색 like % : 모든 문자열, _ : 한 칸에 대한 모든 문자열
select name, height from usertbl where name like '김%';
2. K가 들어간 userid 찾기
-- K 글자가 들어간 아이디에 대한 것만 출력 userid, 이름
select name, userid from usertbl where userid like '%K%';
3. 김씨가 아닌 사람 찾기(like 앞에 not을 붙입니다.)
-- 성이 김씨가 아닌 사람의 이름과 아이디 출력
select name, height from usertbl where name not like '김%';
4. _를 이용해 한글자에 대한 모든 문자열 찾기
-- _한글자에 대한 모든 문자열
select name, height from usertbl where name like '_종신';
2. ANY/ALL/SOME, 서브쿼리(SubQuery, 하위쿼리)
◎ 서브쿼리
▷ 쿼리문 안에 또 쿼리문이 들어있는 것
▷ 서브쿼리 사용하는 쿼리로 변환 예제
◎ 이름과 키가 크거나 같음을 표현해야함
-- 김경호보다 키가 크거나 같은 사람의 이름과 키를 출력
-- 김경호 키
select name, height from usertbl where name like '김경호';
select name, height from usertbl where height >= 177;
위와 같이 사용하면 '김경호'에 저장된 정확한 키를 입력해야 원하는 값이 출력됩니다. 따라서 한 줄로 표현하고 싶으면 서브쿼리를 이용합니다.
1. 김경호보다 키가 큰 사람들의 이름과 키 출력(김경호 포함)
-- 서브 쿼리 : 각각의 쿼리를 조합, 쿼리문 안에 쿼리문 작성
-- 김경호보다 키가 큰 사람의 이름과 키를 출력
select name, height from usertbl where height >=
(select height from usertbl where name like '김경호');
2. 서브 쿼리를 작성했지만 결과 값이 두 개 이상이라서 값이 출력되지 않고 에러가 나타납니다.
-- 경남 지역의 사람보다 키가 큰 사람의 이름과 키를 출력
-- 일반 서브쿼리는 결과값이 2개 이상인 경우 에러 발생
select name, height from usertbl where height >=
(select height from usertbl where addr = '경남');
3. any를 이용한 예제(경남 : 윤종신, 김범수) ▷ 경남 사람 기준으로 둘 중 하나만 조건을 만족하면 출력하는 예제입니다.(OR)
-- 서브쿼리의 결과값이 2개 이상인 경우 : any 서브쿼리
select name, height from usertbl where height >=
any(select height from usertbl where addr = '경남');
4. all을 이용한 예제(경남 : 윤종신, 김범수) ▷경남 사람 기준으로 둘 다 조건을 만족하면 출력하는 예제입니다.(AND)
-- 서브쿼리의 결과값이 2개 이상인 경우 : all 서브쿼리
select name, height from usertbl where height >=
all(select height from usertbl where addr = '경남');
3. 원하는 순서대로 정렬하여 출력 : ORDER BY
▷ 결과물에 대해 영향을 미치지는 않고 출력되는 순서를 조절하는 구문
▷ 기본적으로 오름차순 (ASCENDING) 정렬
-- 칼럼별로 정렬 : ORDER BY 컬럼명
-- 기본 : 오름차순 ASC
-- 내림차순 : desc
-- 아래 둘 다 desc 약자로 사용 가능
-- describe : 테이블
-- descending : 컬럼
-- mdate 기준으로 오름차순으로 정렬
select name, mDate from usertbl order by mdate;
▷ 내림차순(DESCENDING)으로 정렬하려면 열 이름 뒤에 DESC
-- mdate 기준으로 내림차순으로 정렬
select name, mDate from usertbl order by mdate desc;
select name, height from usertbl order by height desc;
▷ ORDER BY 구문을 혼합해 사용하는 구문도 가능
◎ 키가 큰 순서로 정렬하돼 만약 키가 같을 경우 이름 순으로 정렬
select name, height from usertbl order by height desc, name asc;
▷ ASC(오름차순)는 디폴트 값이므로 생략 가능
4. 중복 제거, 개수 제한, 테이블 복사 구문
◎ 중복된 것은 하나만 남기는 distinct
▷ 중복된 것을 골라서 세기 어려울 때 사용하는 구문
▷ 테이블의 크기가 클수록 효과적
▷ 중복된 것은 1개씩만 보여주면서 출력
-- 중복 값 제거
select addr from usertbl;
-- 정렬
select addr from usertbl order by addr;
-- 중복 제거
select distinct addr from usertbl order by addr;
삭제되지는 않고 중복되지 않는 값만 출력
◎ 출력하는 개수를 제한하는 LIMIT
▷ 일부를 보기 위해 여러 건의 데이터를 출력하는 부담 줄임
▷ 상위의 N개만 출력하는 'LIMIT N' 구문 사용
▷ 개수의 문제보다는 MySQL의 부담을 많이 줄여주는 방법
-- 출력 개수를 제한 : limit, 게시판의 목록의 출력 개수 조절, 상품 상위 10개, 우수 고객 등 출력
use employees;
select * from employees;
select emp_no, hire_date from employees order by hire_date asc;
select emp_no, hire_date from employees order by hire_date asc limit 5;
-- 출력 범위 지정 : limit 0, 5 -> 0번째부터 5개를 출력
-- limit 0, 20
-- limit 20, 20
◎ 테이블을 복사하는 CREATE TABLE .. SELECT
▷ 테이블을 복사해서 사용할 경우 주로 사용
▷ CREATE TABLE 새로운 테이블 (SELECT 복사할 열 FROM 기존테이블)
▷ 지정한 일부 열만 복사하는 것도 가능
▷ PK나 FK 같은 제약 조건은 복사되지 않음
-- 테이블 복사 CREATE TABLE .... SELECT(서브쿼리)
-- CREATE TABLE 새로운 테이블명 (SELECT 복사할열 FROM 기존테이블명);
use sqldb;
create table buytbl2 (select * from buytbl);
select * from buytbl;
select * from buytbl2;
create table buytbl3 (select userID, prodName from buytbl);
select * from buytbl3;
-- 사용자별 총 구매 개수
select * from buytbl;
select * from buytbl order by userID;
select userID AS '사용자 아이디', sum(amount) AS '총 구매 개수' from buytbl group by userID;
2. 사용자 ID별 총 구매 금액 그룹화
-- 사용자별 총 구매 금액 = 개별 price * amount
select userID AS '사용자 아이디', sum(price * amount) AS '총 구매 금액' from buytbl group by userID;
3. prodName별 총 판매 금액 그룹화
-- 물품별 총 판매 금액은?
select prodName AS '품목', sum(price * amount) AS '총 판매 금액' from buytbl group by prodName;
4. prodName의 총 판매 개수 그룹화 및 개수 많은 순, 이름 오름차순으로 출력
-- 물품별 총 판매개수, 판매개수가 많은 순으로 출력
select prodName as '품목', sum(amount) as '총 판개 개수'
from buytbl group by prodName order by sum(amount) desc, prodName asc;
◎ GROUP BY와 함께 자주 사용되는 집계 함수
NO
함수명
설명
1
AVG()
평균을 구합니다.
2
MIN()
최소값을 구합니다.
3
MAX()
최대값을 구합니다.
4
COUNT()
행의 개수를 셉니다.
5
COUNT(DISTINCT)
행의 개수를 셉니다(중복은 1개만 인정).
6
STDEV()
표준 편차를 구합니다.
7
VAR_SAMP()
분산을 구합니다.
1. 전체 구매자가 구매한 물품의 개수 평균
-- 총 amount 개수에서 사용자 수를 나누면
select avg(amount) as '평균 구매 개수' from buytbl;
2. 사용자별 구매 개수 펑균
-- 사용자별로 한번에 몇개씩 구매하는가?
select userID, avg(amount) as '평균 구매 개수' from buytbl group by userID;
3. 가장 큰 키를 가진 사람, 작은 키를 가진 회원 출력 1
-- 가장 큰키를 가진 회원, 가장 작은 키를 가진회원
select name, max(height), min(height) from usertbl;
4. 가장 큰 키를 가진 사람, 작은 키를 가진 회원 출력 2
select name, max(height), min(height) from usertbl group by name;
5. 가장 큰 키를 가진 사람, 작은 키를 가진 회원 출력 3
select max(height) from usertbl;
select min(height) from usertbl;
6. 가장 큰 키를 가진 사람, 작은 키를 가진 회원 출력 4
select name, height from usertbl
where height = (select max(height) from usertbl)
or height = (select min(height) from usertbl);
7. usertbl의 모든 사용자 수 출력
-- count 쿼리의 반환 값들의 행 개수를 출력
select count(*) from usertbl;
8. usertbl의 mobile1의 휴대폰이 있는 사용자의 수 출력
select count(mobile1) as '휴대폰이 있는 사용자' from usertbl;
◎ Having절
▷ WHERE와 비슷한 개념으로 조건 제한하는 것이지만, 집계 함수에 대해서 조건을 제한하는 것
▷ HAVING절은 꼭 GROUP BY절 다음에 나와야 함(순서 바뀌면 안됨)
1. 아래의 코드 작성시 오류가 나타납니다.
-- having 절
select userID as '사용자 아이디', sum(price * amount) as '총 구매액'
from buytbl where sum(price * amount) > 1000 -- where 조건이 그룹보다 앞에서 실행
group by userID;
2. having절을 이용해서 조건식 작성(집계 함수 조건 제한)
-- group by 에서 조건을 사용하기 위해 Having 절 이용
select userID AS '사용자 아이디', sum(price * amount) as '총 구매액'
from buytbl
group by userID
having sum(price * amount) > 1000;
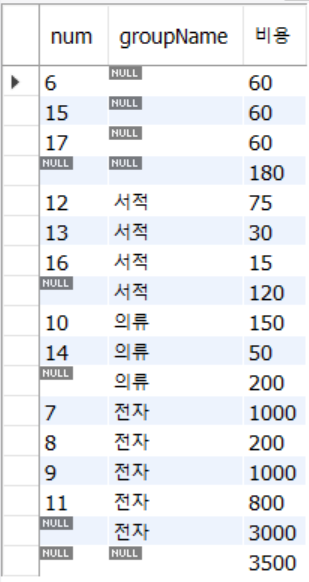
◎ ROLLUP
▷ 총합 또는 중간 합계가 필요한 경우 사용
▷ GROUP BY절과 함께 WITH ROLLUP문 사용 ▶ 분류(groupName) 별로 합계 및 그 총합 구하기
-- rollup
select num, groupName, sum(price * amount) as '비용'
from buytbl
group by groupName, num
with rollup;
분류별로 합계가 구해집니다.
◎ 단축키 팁
줄 복사 : CONTROL + D
줄 삭제 : CONTROL + L
WHERE, BETWEEN, IN, LIKE, 서브쿼리 등을 이용한 구문들을 사용해보았습니다!