[DB_MySQL] 이것이 MySQL이다 ch09 인덱스 1(클러스터형 인덱스, 보조 인덱스)
bobo122023. 2. 9. 19:37
728x90
1. 인덱스(Index)란? ▷ 책의 <찾아보기>의 개념과 비슷 ▷데이터를 좀 더 빠르게 찾을 수 있도록 해주는 도구
◎ 인덱스의 장단점
▷장점
▶ 검색 속도가 무척 빨라질 수 있음 (항상 그런 것은 아님)
→ 책도 너무 두꺼우면 찾기 어렵기 때문입니다.
▶쿼리의 부하가 줄어들어 시스템 전체의 성능 향상
▷ 단점
▶ 인덱스가 데이터베이스 공간을 차지해서 추가적인 공간 필요
→대략 데이터베이스 크기의 10% 정도의 추가 공간 필요
▶ 처음 인덱스 생성하는데 시간 소요
▶ 데이터의 변경 작업 (Insert, Update, Delete)이 자주 일어나는 경우 성능이 나빠질 수도 있음
◎인덱스의 종류
▷ 클러스터형 인덱스 (Clustered Index)
▶기본키
▶ ‘영어 사전’과 같은 책
▶ 테이블 당 한 개만 지정 가능
▶행 데이터를 인덱스로 지정한 열에 맞춰 자동 정렬
▶ 기본키로 지정되면 오름차순으로 자동 정렬됩니다.
use sqldb;
select * from usertbl;
-- 기본키 변경 :
-- 1. buytbl의 외래키 설정 제거
-- 2. usertbl의 기본키 제거
-- 3. usertbl의 name 컬럼을 기본키 지정
alter table buytbl
drop foreign key buytbl_ibfk_1;
alter table usertbl
drop primary key;
alter table usertbl
add constraint pk_name primary key (name);
-- 이름 기준으로 자동 정렬 되어 있는 것을 확인할 수 있음
select * from usertbl;
desc usertbl;
-- 테이블 생성시에 제약조건 primary key 또는 unique를 사용하면 자동으로 인덱스가 생성
show index from usertbl;
▷ 보조 인덱스 (Secondary Index)
▶ UNIQUE
▶ 책 뒤에 <찾아보기>가 있는 일반 책
▶ 테이블당 여러 개도 생성 가능
1. 인덱스 실습(기본키 설정)
create table tbl1
(
a int primary key,
b int,
c int
);
show index from tbl1;
2. 인덱스 실습(기본키와 Unique 추가)
create table tbl2
(
a int primary key,
b int unique,
c int unique
);
show index from tbl2;
-- tbl2 0 PRIMARY 1 a A 0 BTREE
-- tbl2 0 b 1 b A 0 YES BTREE
-- tbl2 0 c 1 c A 0 YES BTREE
drop table tbl2;
3. 인덱스 실습(기본키와 Unique 추가 2)
-- unique index : 중복 값이 없는 인덱스(클러스터 인덱스 : primary key, unique)
-- nonunique index : 중복 값이 있는 인덱스(1 : nonunique, 0 : unique)
create table tbl3
(
a int primary key,
b int unique,
c int unique,
d int
);
show index from tbl3;
4. 기본키 없이 Unique만 지정UNIQUE에 클러스터형 인덱스 지정
-- unique만 사용
create table tbl4
(
a int unique,
b int unique,
c int unique,
d int
);
show index from tbl4;
unique에 not null이 포함되면 클러스터형 인덱스로 지정됨
5. UNIQUE에 클러스터형 인덱스 지정
-- unique와 not null 동시 사용
-- primary가 없고 unique가 not null이면 클러스터 인덱스로 사용
-- unique는 보조 인덱스
create table tbl5
(
a int unique not null,
b int unique,
c int unique,
d int
);
show index from tbl5;
6. unique에 not null과 primary키를 동시 지정
-- unique와 not null, primary key 동시 사용
create table tbl6
(
a int unique not null, -- 클러스터 인덱스 : 자동 정렬
b int unique, -- 보조 인덱스 : 정렬x
c int unique,
d int primary key -- 클러스터 인덱스 : 자동 정렬
);
show index from tbl6;
-- 기본 값이 먼저 우선적으로 자동 정렬
-- primary key로 지정한 열은 클러스터형 인덱스가 생성
-- unique not null로 지정한 열은 클러스터형 인덱스가 생성
-- unique 또는 unique null로 지정한 보조 열은 보조 인덱스가 생성
-- primary key와 unique not null이 있으면 primary key로 지정한 열을 우선 클러스터형 인덱스가 생성
-- primary key로 지정한 열로 데이터가 오름차순 정렬된다.
◎ 인덱스의 특징 ▷ PRIMARY KEY로 지정한 열은 클러스터형 인덱스가 생성 ▷UNIQUE NOT NULL로 지정한 열은 클러스터형 인덱스 생성 ▷UNIQUE(또는 UNIQUE NULL)로 지정한 열은 보조 인덱스 생성 ▷PRIMARY KEY와 UNIQUE NOT NULL이 존재 ▷PRIMARY KEY와 UNIQUE NOT NULL이 있으면 PRIMARY KEY에 지정한 열에 우선 클러스터형 인덱스 생성 ▷PRIMARY KEY로 지정한 열로 데이터가 오름차순 정렬
2. 인덱스의 내부 작동
◎ B-Tree(Balanced Tree, 균형 트리) ▷ 자료 구조’에 나오는 범용적으로 사용되는 데이터 구조 ▷인덱스 표현할 때와 그 외에도 많이 사용
◎페이지 분할 ▷인덱스 구성시 SELECT 문의 효율성 향상 ▷인덱스 구성시 INSERT 문이 일어날 경우 속도 저하되는 단점 ▶주어진 공간 이상으로 데이터 들어가면 페이지 분할 일어남
◎ 클러스터형 인덱스와 보조 인덱스의 구조 ▷ 인덱스 없는 테이블의 예시
-- 인덱스가 없는 테이블 : 데이터를 입력한 순서대로 출력이 된다.
create database if not exists testdb;
use testdb;
drop table if exists clustertbl;
create table clustertbl -- cluster table의 약자
(
userID CHAR(8),
name VARCHAR(10)
);
INSERT INTO clustertbl VALUES('LSG', '이승기');
INSERT INTO clustertbl VALUES('KBS', '김범수');
INSERT INTO clustertbl VALUES('KKH', '김경호');
INSERT INTO clustertbl VALUES('JYP', '조용필');
INSERT INTO clustertbl VALUES('SSK', '성시경');
INSERT INTO clustertbl VALUES('LJB', '임재범');
INSERT INTO clustertbl VALUES('YJS', '윤종신');
INSERT INTO clustertbl VALUES('EJW', '은지원');
INSERT INTO clustertbl VALUES('JKW', '조관우');
INSERT INTO clustertbl VALUES('BBK', '바비킴');
select * from clustertbl;
-- 인덱스 없는 테이블 <- 클러스터형 인덱스 추가 : primary key(자동정렬)
alter table clustertbl
add constraint PK_clustertbl_userID
primary key (userID);
select * from clustertbl;
▷ 클러스터형 인덱스 구성한 테이블 구조 ▷userID를 Primary Key로 지정하면 클러스터형 인덱스로 구성됨
▷ 클러스터형 인덱스 구성한 테이블 구조
▷ 보조 인덱스 구성한 테이블 구조
-- 보조 인덱스 추가
create table secondarytbl
(
userID CHAR(8),
name VARCHAR(10)
);
INSERT INTO secondarytbl VALUES('LSG', '이승기');
INSERT INTO secondarytbl VALUES('KBS', '김범수');
INSERT INTO secondarytbl VALUES('KKH', '김경호');
INSERT INTO secondarytbl VALUES('JYP', '조용필');
INSERT INTO secondarytbl VALUES('SSK', '성시경');
INSERT INTO secondarytbl VALUES('LJB', '임재범');
INSERT INTO secondarytbl VALUES('YJS', '윤종신');
INSERT INTO secondarytbl VALUES('EJW', '은지원');
INSERT INTO secondarytbl VALUES('JKW', '조관우');
INSERT INTO secondarytbl VALUES('BBK', '바비킴');
-- 유니크를 이용한 보조 인덱스 생성 (자동 정렬 x)
alter table secondarytbl
add constraint uk_secondarytbl_userID
unique (userID);
select * from secondarytbl;
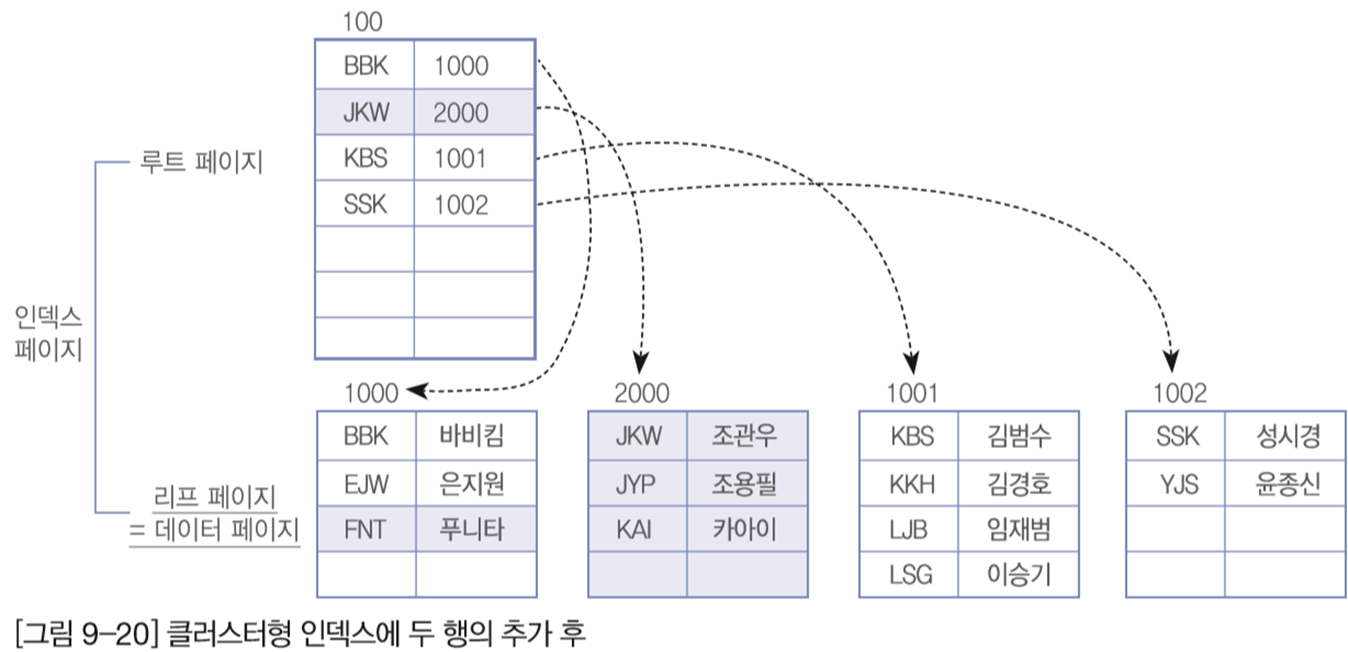
▷클러스터 인덱스에 새로운 데이터 입력
▷ 보조 인덱스에 새로운 데이터 입력
◎ 클러스터형 인덱스의 특징
1. 클러스터형 인덱스의 생성 시에는 데이터 페이지 전체 다시 정렬 ▷ 이미 대용량의 데이터가 입력된 상태라면 업무시간에 클러스터형 인덱스 생성하는 것은 심각한 시스템 부하
2. 인덱스 자체의 리프 페이지가 곧 데이터 ▷ 인덱스 자체에 데이터가 포함되어 있음
3. 클러스터형 인덱스는 보조 인덱스보다 검색 속도는 더 빠름 ▷ 데이터의 입력/수정/삭제는 더 느림
4. 클러스터형 인덱스는 성능이 좋지만 테이블에 한 개만 생성 가능 ▷ 어느 열에 클러스터형 인덱스 생성하는지에 따라 시스템의 성능이 달라짐
◎보조 인덱스의 특징
1. 보조 인덱스 생성시 별도의 페이지에 인덱스 구성
2. 인덱스 자체의 리프 페이지는 데이터가 아니고 데이터가 위치하는 주소 값(RID)
3. 클러스터형보다 검색 속도는 더 느림 ▷ 데이터의 입력/수정/삭제는 덜 느림
4. 보조 인덱스는 여러 개 생성할 수 있음 ▷ 남용할 경우에는 시스템 성능을 떨어뜨리는 결과 발생
◎ 클러스터형 인덱스와 보조 인덱스가 혼합되어 있을 경우
1. 보조 인덱스를 검색한 후에 다시 클러스터형 인덱스를 검색해야 하므로 약간의 손해를 볼 수도 있겠지만, 데이터의 삽입 때문에 보조 인덱스를 대폭 재구성하게 되는 큰 부하는 걸리지 않음
2. 보조 인덱스와 혼합되어 사용되는 경우 되도록이면 클러스터형 인덱스로 설정할 열은 적은 자릿수의 열을 선택하는 것이 바람직함
3. 인덱스를 검색하기 위한 일차 조건 ▷ WHERE절에 해당 인덱스를 생성한 열의 이름이 나와야 함 ▷WHERE절에 해당 인덱스를 생성한 열 이름이 나와도 인덱스를 사용하지 않는 경우도 많음
데이터를 좀 더 빠르게 찾아보기 위해서 index를 사용합니다. 기본키도 index 기능이 있기 때문에 자동으로 오름차순 정렬이 되고 외래키, Unique Key도 마찬가지 입니다! 하지만 기본키가 제일 우선순위가 높네요!!!